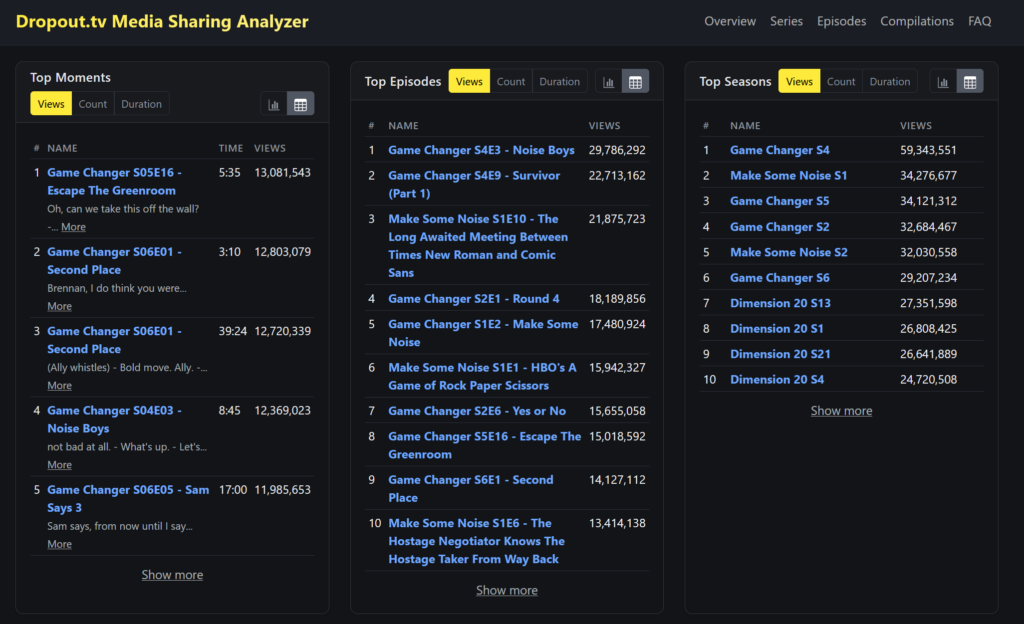
Dropout.tv make some of the best television today with shows such as Game Changer, Make Some Noise, and Dimension 20. As a fan, I began wondering: what is the most popular episode on the platform? What is the moment that resonates most with the community?
That’s when the idea for the idea for this project began.
With the lack of viewership statistics, answering these questions would be impossible if it wasn’t for how passionate and dedicated Dropout fans are. As such, they have made (and keep making) hundreds of compilations from Dropout content across all shows and post them on YouTube for other fans to enjoy.
Thanks to YouTube viewership data, we now have a rough proxy for the popularity of moments and episodes: the more popular an episode/moment is, the more compilations there will be, and in turn, the more views it the compilations will have.
Is it perfect? No. Will it do for our purposes? Absolutely.
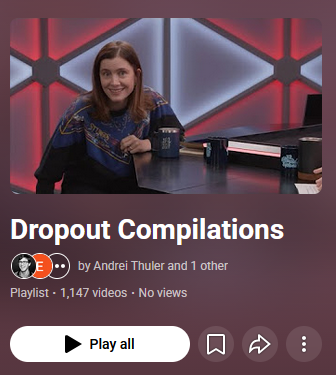
After several hours, I now had this massive YouTube playlist with over a thousand Dropout compilations.
We have many hours of compilations, but now what? I certainly was not going to go through each one and manually figure out what episode each clip belongs to. Time for some Python automation.
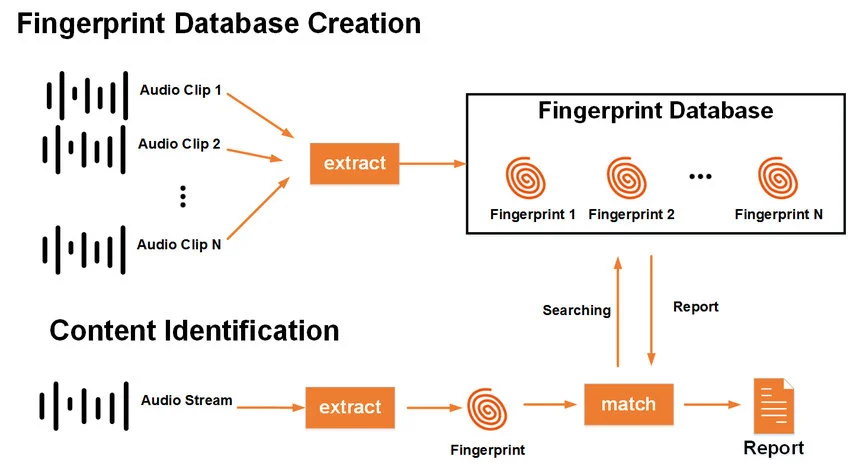
The plan was to use fingerprinting, the same method powering Shazam and other music-matching services. Below is a simplified version of how it would work in our case:
- For each Dropout episode, do the following:
- Create a “fingerprint” from the episode audio
- Store it in a database
- For each compilation, do the following:
- Create a “fingerprint” of the compilation audio
- Match it against the database of episode fingerprints
- Record every fingerprint match
Not wanting to reinvent the wheel, I started looking for Python packages that did exactly what I wanted to do, and I was a bit surprised with the apparent sparsity of packages in this domain. I ended up going with a fork of audfprint (whose last commit was in 2019) suitably called audfprint2.
We only need to perform one “tweak” for audfprint2 to work perfectly for our purpose: the size of the fingerprint database is limited to a specific size, and since we will definitely be exceeding it (by a lot), I wrote a few functions to handle having multiple databases working together.
Skipping through until I have the audio files of the episodes and the compilations, we can test everything it in a notebook (screenshot below).
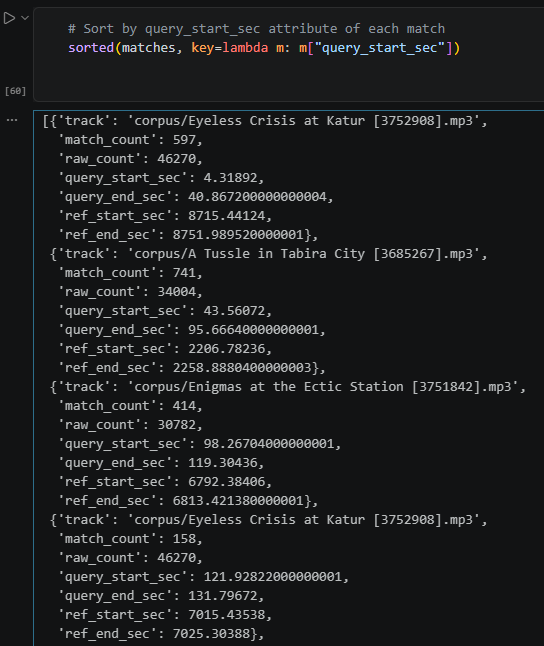
Given a compilation, we can now detect each clip within and what episode it is from. In the example above, we can see that the compilation “Cloudward, Ho! moments that make me cry laugh” begins with a clip from Eyeless Crisis at Katur (S26E13) from 4s to 41s. Then, from 43s to 95s, it has a clip from A Tussle in Tabira City (S26E05).
It works! Now time to process every episode and compilation. (well… for simplicity I decided to only process Game Changer, Make Some Noise, Dimension 20, Dimension 20 Live, and Dimension 20’s Adventuring Party, but I may add more later)
I made myself a simple web UI to help fingerprint all episodes and compilations and to perform all the matching. Processing the hundreds of hours of audio took hours.
After everything was done processing, I had a database with 31,000 matches.
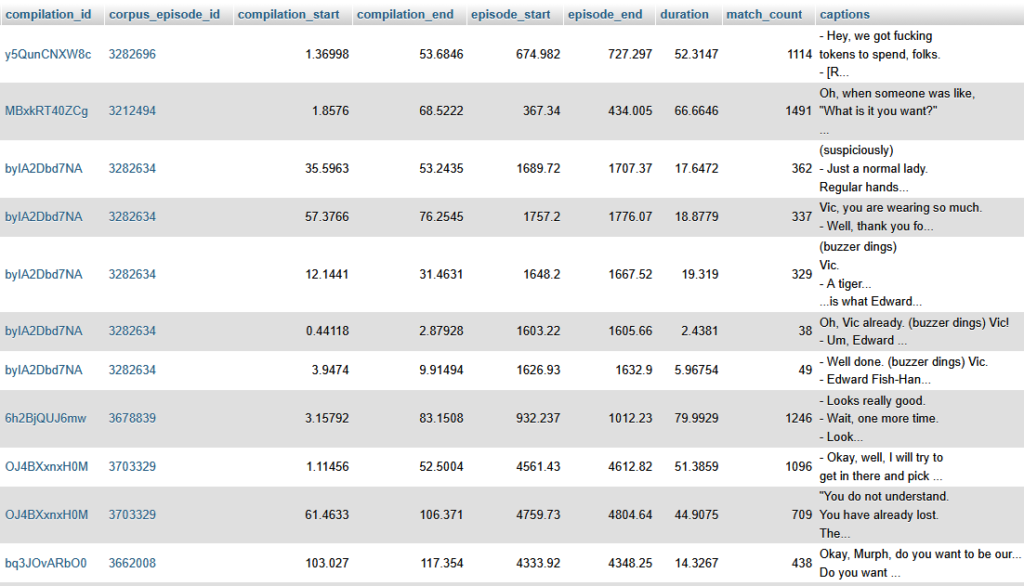
All that was left was actually answering our questions with the data we had collected.
One web app later, and there we go!
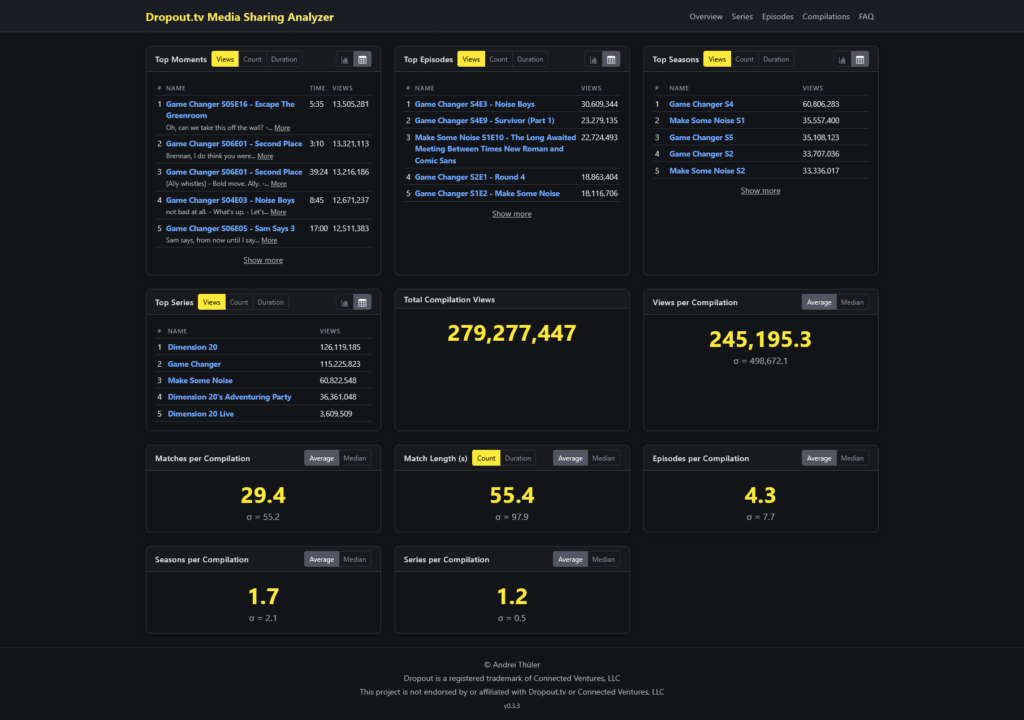
According to these data, the most popular moment is early in Game Changer’s Escape the Greenroom when Brennan Lee Mulligan exclaims “You want bits? You let me out of the room for bits,” and the most popular episode is Game Changer’s Noise Boys.