On July 14th, 2025, Dropout TV released the latest episode of Game Changer: Fool’s Gold (Season 7 Episode 8). The premise of the episode is that the three players (Trapp, Jordan, and Rekha) compete in funding the viral video idea which will get the most social media views over the next month. I immediately decided to build a scoreboard so anyone could check the players’ scores live.

First, I had to get the links of all 10 videos which were posted across the fractured social media landscape of today. (I’m purposefully not scoring Twitter engagement)

The score for each of the players will then be computed as such:
- Trapp: Glue, Cracks, 0.5 * Puppy Bowl, 0.5 * Holes, 1/3 * Brennan
- Jordan: Kings, Hair, 0.5 * Car Wash, Breast Milk, 1/3 * Brennan
- Rekha: Dimension 20, 0.5 * Car Wash, 0.5 * Puppy Bowl, 0.5 * Holes, 1/3 * Brennan
While this was relatively painless, now I had to pull in data for each social network.
YouTube, Tumblr and Bluesky made it very easy as they had official APIs I could use to pull in those data.
TikTok and Meta (Instagram and Threads) *technically* have APIs, but you cannot use them to get data on content that isn’t yours (and even then it wouldn’t give me the data I’m looking for), so I had to resort to data scraping (ew). This is a very inelegant solution, but I wouldn’t have to resort to this if they had made an official API available.
While the scraped TikTok data look fine, the Instagram and Threads data do not, varying wildly with every data point. Therefore, to preserve the overall accuracy of the scores, I decided to exclude Instagram and Threads from the calculations by default unless the user manually chooses to include them.


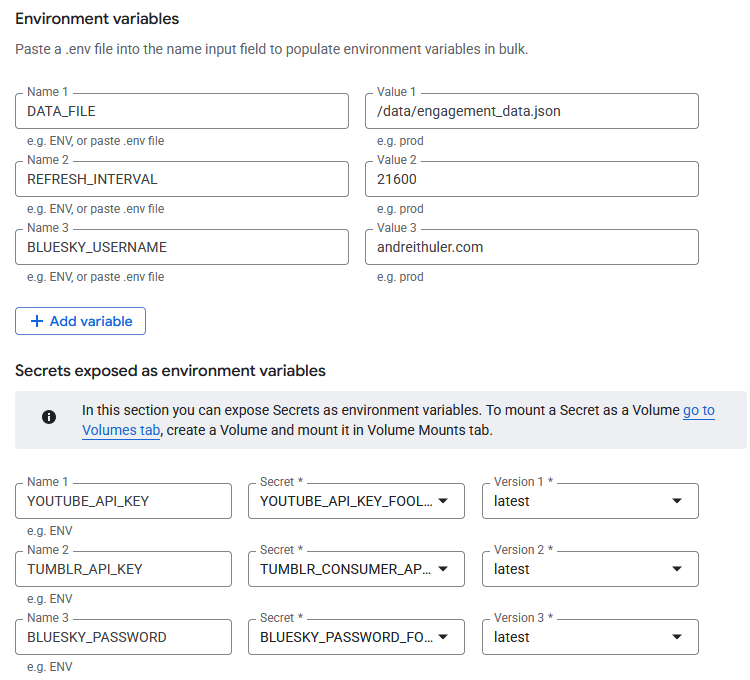
Now that I had all this social media data, I had to store it somehow. Given the self-imposed requirement to keep this project as light as possible, I didn’t want to spin up an entire database service, so I opted to store all the fetched data in a single JSON file.
{
"kings":[
{
"timestamp":123456,
"total_views": 123,
"total_likes": 123,
"total_comments": 123,
"views_threads": 123,
"likes_threads": 123,
"comments_threads": 123,
"views_instagram": 123,
...
},
{"timestamp":1234212, ...}
],
"car_wash": ...,
...
}While obviously inefficient, the total amount of data stored is quite limited and in a format that makes it easy for the web app to fetch. This has worked wonderfully so far.
After working up a quick frontend showing the current ranking of all the videos as well as the players’ scores, it was time to deploy it.
Trying to keep the project as low-cost as possible, I deployed it on Google Cloud Run while storing the data JSON file in a Google Cloud Storage bucket mounted to the instance as a volume. The Google Cloud Console’s Web GUI made it extremely easy to continuously deploy the project whenever changes were made on GitHub.
I got stuck for several hours at this point before I could publish because DNS propagation was being extremely slow, but it eventually completed and my subdomain foolsgold.andreithuler.com was correctly pointing to the Google servers and Google wired everything internally to connect it to my Cloud Run instance.
The only setting I needed “easy” access to was the “Refresh Interval” which dictates how frequently the social media data should be refreshed, so I exposed it as an environment variable. For the first week after launch it was set to 3600 (1h), after which I increased it to 21600 (6h).
I released the project on Tuesday, July 15th, 2025, one day after the episode aired and posted it on my social media. The project received 81 users the first day and 88 the second, reducing to only a few people a day beyond that.

Over the weekend, I accidentally restricted my YouTube Data API key, making the site fall back to web scraping for July 20-22. I immediately reinstated the key once I noticed, but I now had missing data, so I decided to disable the display of YouTube data by default to not spook any website users.

This was a very fun project! I got feedback from some users who said it made their day, and that’s what it’s all about!
Dropout if you’re reading this, contact me! Let’s do something together 😀